Where features are active
For every feature, we collected images that fire the feature most strongly. Interestingly, the images reflect similar objects or concepts, like folders (down.2.1.#0), kitchen islands (down.2.1.#1), and so on. Note that the activation regions differ from quite scattered in the blocks down.2.1 and up.0.1 to more localized and concentrated on mid.0 and up.0.0.
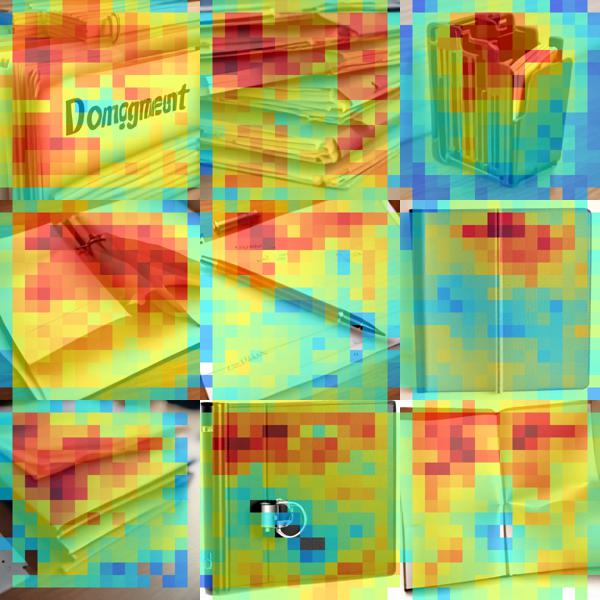
down.2.1 #0
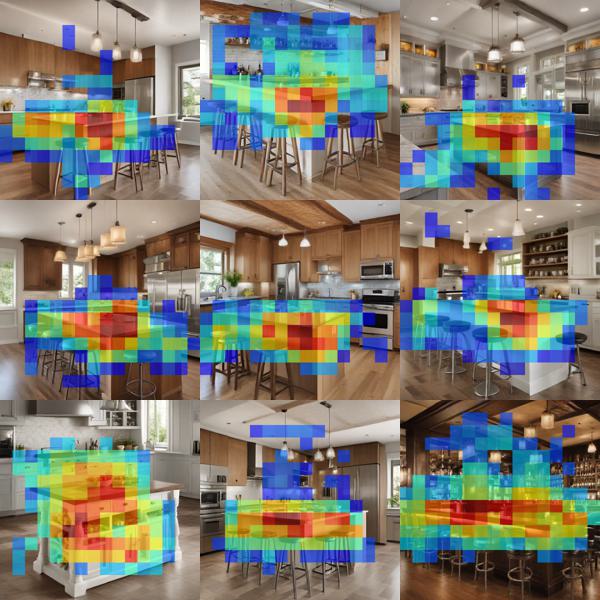
down.2.1 #1
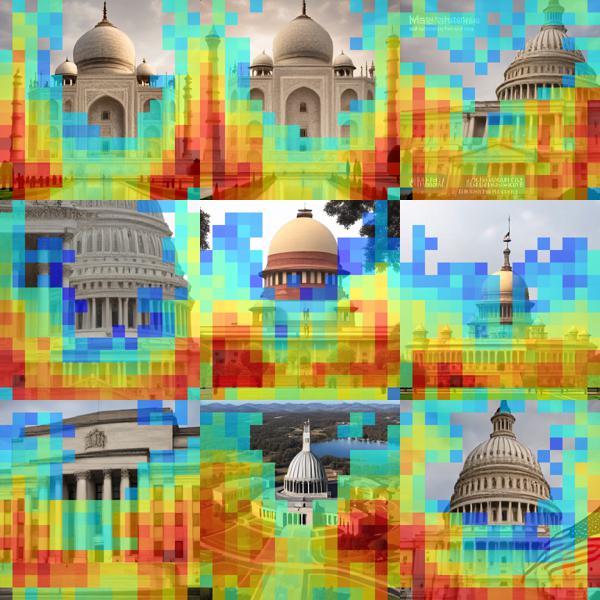
down.2.1 #2

mid.0 #3

mid.0 #50

mid.0 #609

up.0.1 #0
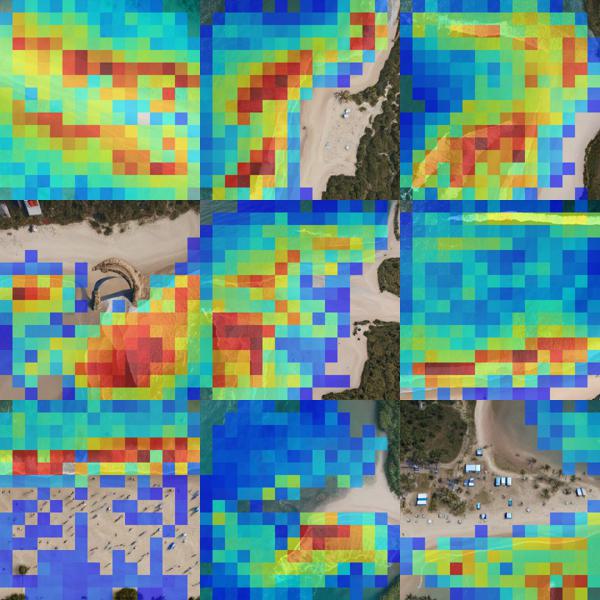
up.0.1 #1

up.0.1 #2

up.0.0 #0

up.0.0 #1

up.0.0 #2
These features are highly active during the image generation process. Notably, they appear to encode both concrete objects as well as abstract concepts.

